数据科学导论复习
第一章 大数据概述
大数据定义
- 大数据是指无法在一定时间内用常规软件工具对其内容进行抓取、管理和处理的数据集合
大数据特点
- 数据量大
- 数据种类多样
- 高实时性
- 数据价值巨大但价值密度低
数据科学基本流程
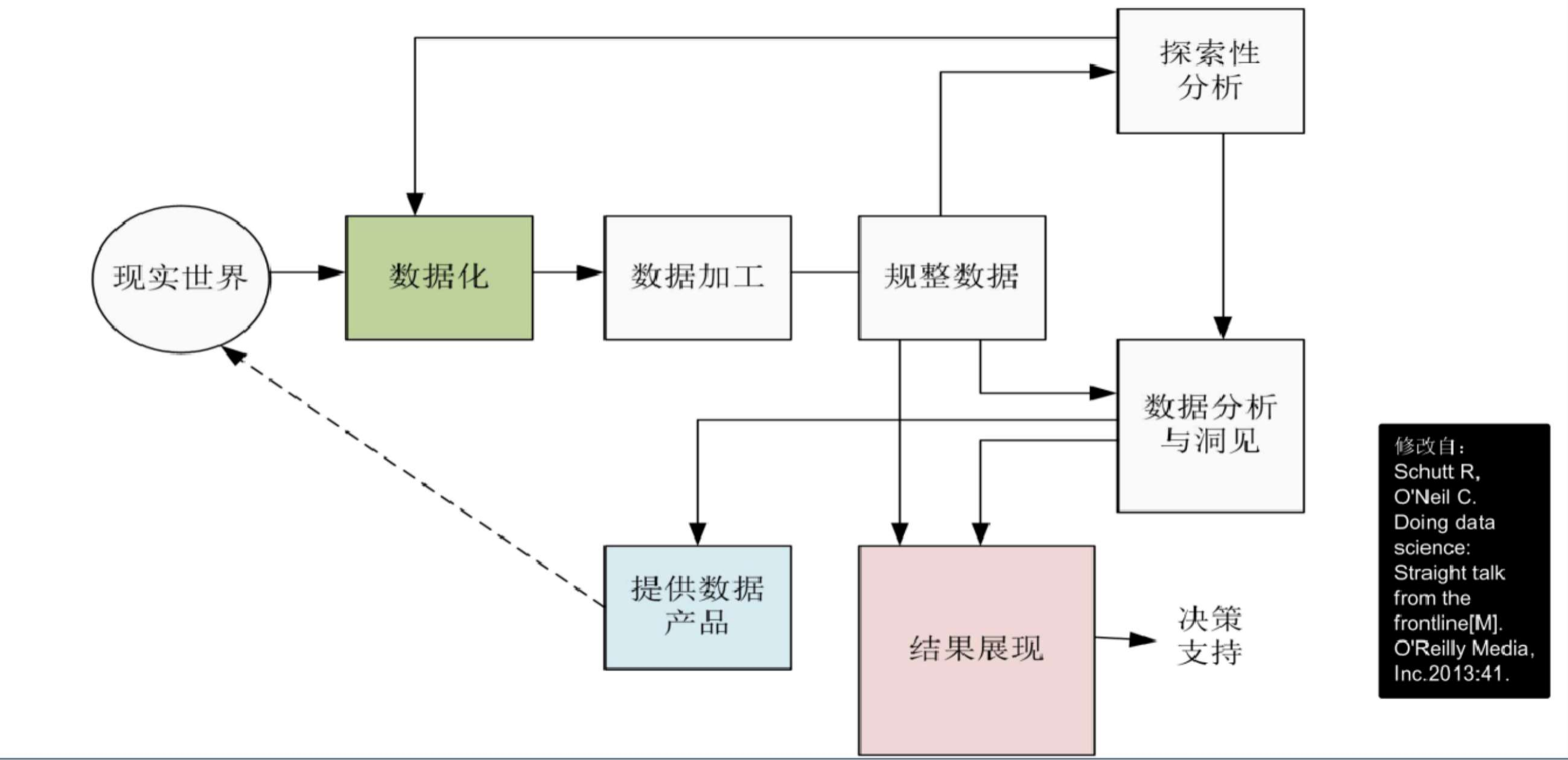
数据的不同处理模式
- 批处理
- 数据先保存起来,然后分析(全量数据)
- 响应时间分钟/小时计
- 流式处理
- 数据及时处理,处理过后一般不保存
- 响应时间毫秒计
- 交互式处理
- 数据先保存起来,然后查询(部分数据)
- 响应时间秒级
大数据应用
- 社会网络大数据
- 交通大数据
- 文本大数据
- 时空数据
第二章 数据存储
数据的分类
- 结构化数据
- 可以使用关系型数据库表示和存储的数据,拥有固定结构
- 半结构化数据
- 弱结构化,虽然不符合关系数据模型的要求,但是含有相关标记(自描述结构),分割实体及期属性。如XML,JSON等
- 非结构化数据
- 没有固定数据结构,或很难发现统一数据结构的数据
- 文档、文本、图片、视频、音频等
关系型数据库和NoSQL
SQL语言的类型
- 类别一:Data Definition Language (DDL) 数据定义语言
- 类别二:Data Manipulation Language (DML) 数据操作语言(增删改查)
- 类别三: Data Control Language(DCL):数据控制语言,用来定义访问权限和安全级别
- 类别四:Data Query Language(DQL):数据查询语言,用来查询记录(数据)。这些语言通过DBMS来操作DB,DBMS是一个系统
第三章 大数据计算
HDFS
- Hadoop Distributed File System(HDFS),这是在由普通服务器组成的集群上运行的分布式文件系统,支持大数据的存储;通过多个节点的并行IO,提供极高的吞吐能力
- 一个HDFS集群,一般由一个NameNode和若干DataNode组成,分别负责元信息的管理和数据块的管理
- HDFS支持TB级甚至PB级大小文件的存储,它把文件划分成数据块(Block),分布到多台机器上进行存储
- 为了保证系统的可靠性,HDFS把数据块在多个节点上进行复制(Replicate)
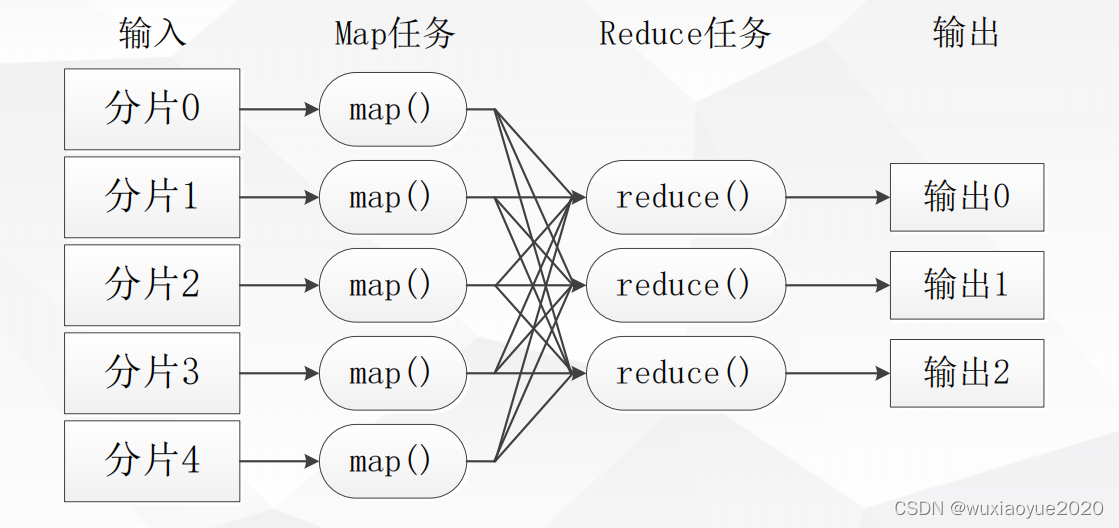
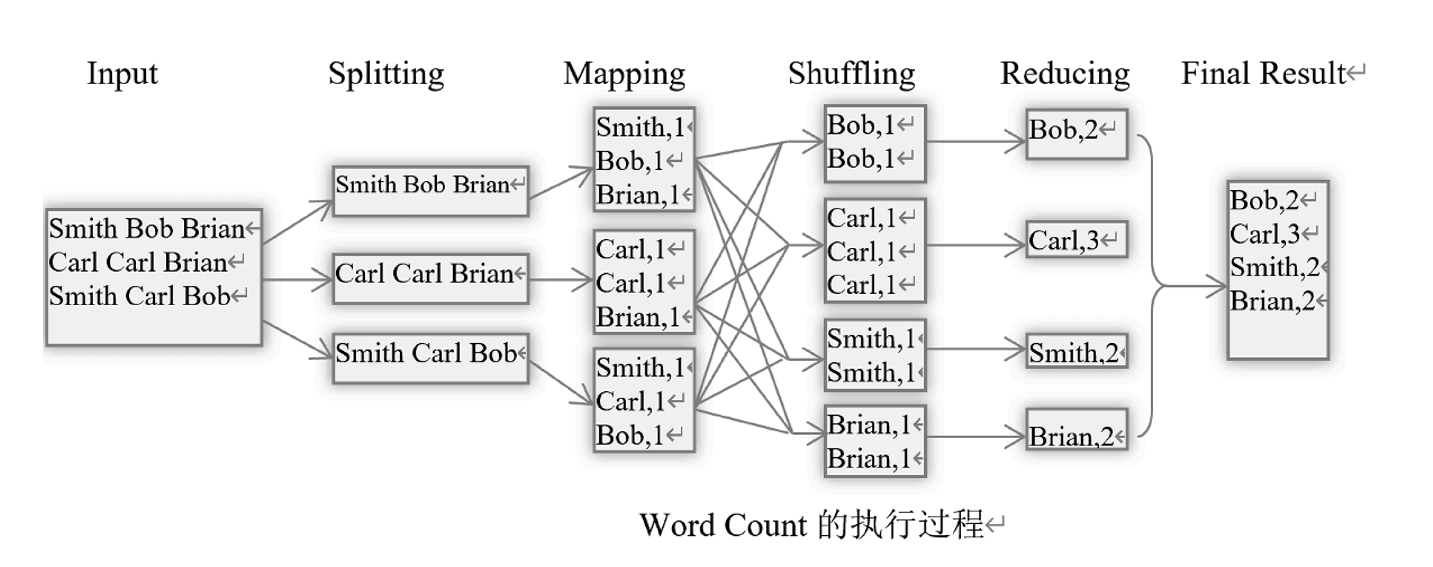
Hadoop MapReduce
- 一种支持大数据处理的编程模型
- MapReduce并行编程模型把计算过程分解为两个主要阶段,即Map 阶段和Reduce阶段。
- Map函数处理<Key,Value>对,产生一系列的中间<Key,Value>对
- Reduce函数合并所有具有相同Key值的中间键值对,计算最终结果
- MapReduce计算模型,可以形式化地表达成Map:<k1,v1>-> list<k2,v2>, Reduce:<k2,list(v2)>->list<k3,v3>
- 缺点
- 仅支持MapReduce计算模型
- MapReduce通过磁盘数据交换,效率低下
Spark
RDD
第四章 数据采集与整理
检测冗余属性
- Pearson积距相关系数
- 卡方检验
数据的距离
- 欧几里得距离
- 汉明距离
- 明氏距离
- 马氏距离
数据的相似度
- Jaccard相关系数
- 余弦相似度
数据的相关性
- Pearson相关系数
有序数据和无序数据
- 无序数据:每个数据样本的不同维度没有顺序关系
- 有序数据:有
有序数据的距离测量
- Spearman Rank(斯皮尔曼等级)相关系数
第八章 数据分析方法
机器学习基本流程
- 业务场景分析
- 数据处理
- 训练机器模型和评价
- 使用机器学习模型
机器学习分类
- 有监督学习
- 对于样本有输入X和预期输出Y
- 无监督学习
- 样本数据无需人工标注,无目标值
- 半监督学习
- 一小部分标注数据,大部分无标注数据
- 强化学习
- 对系统和环境建模,通过与外界不断交互,获得反馈,修正机器学习模型
第十章 数据可视化
数据可视化工具
- Google Refine
- Echarts
- Tableau
- Processing
- D3(JS)
- ColorBrewer
第十一章 文本分析
抓取控制
meta robots
<meta name="robots" content="...">中的content有多种取值index:允许搜索引擎索引该页面。
noindex:禁止搜索引擎索引该页面。
follow:允许搜索引擎跟踪该页面上的链接。
nofollow:禁止搜索引擎跟踪该页面上的链接。
all:等同于index, follow,允许索引页面并跟踪链接。
none:等同于noindex, nofollow,禁止索引页面并跟踪链接。
noarchive:禁止搜索引擎缓存该页面的快照。
nosnippet:禁止搜索引擎在搜索结果中显示页面的摘要。
max-snippet:[number]:限制搜索引擎在搜索结果中显示的页面摘要的最大字符数。
noodp:禁止搜索引擎使用开放目录项目(ODP)中的描述作为页面的摘要。
notranslate:禁止搜索引擎提供该页面的翻译版本。
robots.txt
1
2User-agent: Googlebot // 不允许谁抓取,不允许所有为*
Disallow: / // 不允许抓取的页面路径
纵容恶意爬虫的危害
- 额外带宽负担
- 核心文本被爬取
- 注册用户被扫描
- 点击欺诈
独热编码
词的独热表示是一种最简单最直接的词的向量化表示方式。主要步骤包含两步:
- 对需要用到的文本中所有词进行编码(假设共用N个词),每个词有唯一的下标(0~N)。
- 根据词下标 i 生成一个长度为N的向量,除了第i位为1外,其他位都为0。
绝对词频
- 每个文档表示为一个n维向量,每一维对应一个单词,值为单词出现的次数
相对词频TF
- 该词出现的次数/总词数
逆文档频率IDF
- lg(文档总数/含有该词的文档数)
TF-IDF
- 相对词频*逆文档频率
数据科学导论复习
https://sdueryrg.github.io/2024/12/26/数据科学导论复习/