人工智能导论复习
第四章 不确定性推理方法
可信度方法
推理
- 从已知事实(证据)出发,通过运用相关知识逐步推出结论或者证明某个假设成立或不成立的思维过程。
不确定性推理
- 从不确定性的初始证据出发,通过运用不确定性的知识,最终推出具有一定程度的不确定性但却是合理或者近乎合理的结论的思维过程。
可信度
- 根据经验对一个事物或现象为真的相信程度。
C-F模型
- 基于可信度表示的不确定性推理的基本方法。
知识的不确定性表示

- CF(H,E)的取值范围: [-1,1]。
- 若由于相应证据的出现增加结论 H 为真的可信度,则 CF(H,E)> 0,证据的出现越是支持 H 为真,就使CF(H,E) 的值越大。
- 反之,CF(H,E)< 0,证据的出现越是支持 H 为假,CF(H,E)的值就越小。
- 若证据的出现与否与 H 无关,则 CF(H,E)= 0。
证据不确定性的表示
$$
CF(E)=0.6: E的可信度为0.6
$$
- 证据E的可信度取值范围:[-1,1] 。
- 对于初始证据,若所有观察S能肯定它为真,则CF(E)= 1。
- 若肯定它为假,则 CF(E) = –1。
- 若以某种程度为真,则 0 < CF(E) < 1。
- 若以某种程度为假,则 -1 < CF(E) < 0 。
- 若未获得任何相关的观察,则 CF(E) = 0。
- 静态强度CF(H,E):知识的强度,即当 E 所对应的证据为真时对 H 的影响程度。
- 动态强度 CF(E):证据 E 当前的不确定性程度。
组合证据不确定性的算法
- 组合证据:多个单一证据的合取
$$
E=E1 \space\space AND \space\space E2 \space\space AND …AND \space\space En
$$
$$
则CF(E)=min \lbrace CF(E_1),CF(E_2),CF(E_3),…,CF(E_n) \rbrace
$$
- 组合证据:多个单一证据的析取
$$
E=E1 \space\space OR \space\space E2 \space\space OR… OR \space\space En
$$
$$
则CF(E)=max\lbrace CF(E_1),CF(E_2),CF(E_3),…,CF(E_n) \rbrace
$$
不确定性的传递算法
- C-F模型中的不确定性推理:从不确定的初始证据出发,通过运用相关的不确定性知识,最终推出结论并求出结论的可信度值。结论 H 的可信度由下式计算:
$$
CF(H)=CF(H,E)*max\lbrace 0,CF(E)\rbrace
$$
结论不确定性的合成算法


结论不确定性的合成算法例子





证据理论
样本空间
- 设 D 是变量 x 所有可能取值的集合,且 D 中的元素是互斥的,在任一时刻 x 都取且只能取 D 中的某一个元素为值,则称 D 为 x 的样本空间。
基本概率分配函数
- 基本概率分配函数(Basic Probability Assignment, BPA)是从集合 $2^\Omega $到区间$[0, 1]$的映射,满足以下两个条件:
$$
m: 2^\Omega \rightarrow [0, 1]
$$
- $$m(\emptyset) = 0$$
- $$\sum_{A \subseteq \Omega} m(A) = 1$$
其中,$m(A)$表示对命题A的支持程度。如果 $m(A) > 0$ ,则称A为一个焦元(focal element)。
则 $M: 2^\Omega \rightarrow [0, 1] $ 上的基本概率分配函数,$ M(A): A$的基本概率数。
例如,设 A={红},M(A)=0.3:命题“x是红色”的信任度是0.3。
信任函数
$$
Bel(A) = \sum_{B \subseteq A} m(B)
$$
- 其中, Bel(A) 表示对命题A的总的信任程度。根据基本概率分配函数的特点,我们可以知道:
$$
Bel(\emptyset) = m(\emptyset) = 0
$$
$$
Bel(\Omega) = \sum_{B \subseteq \Omega} m(B) = 1
$$
$$
Bel(A): A \text{ 的信任度。}
$$
似然函数
$$
\text{似然函数(Plausibility Function)定义如下:}
$$
$$
Pl(A) = \sum_{B \cap A \neq \emptyset} m(B)
$$
- 其中,$Pl(A) $ 表示对命题 $ A $ 的似然程度。
- 根据基本概率分配函数的特点,我们可以知道:
$$
Pl(\emptyset) = 0
$$
$$
Pl(\Omega) = 1
$$
$$
Pl(A): A \text{ 的似然度。}
$$
- 例如

概率分配函数的正交和(证据的组合)
- 设$M_1$和$M_2$是两个概率分配函数,则其正交和$M=M_1 \oplus M_2$
$$M(\emptyset)=0$$
$$M(A) = \frac{1}{1 - k}\sum_{x \cap y = A}M_1(x)M_2(y)$$
$$K = 1- \sum_{x \cap y = \emptyset}M_1(x)M_2(y)=\sum_{x \cap y \neq \emptyset}M_1(x)M_2(y)$$ - 如果$K \neq 0$,则正交和 M也是一个概率分配函数;
- 如果$K = 0$,则不存在正交和 M,即没有可能存在概率函数,称$M_1$与$M_2$矛盾。
- 例


基于证据理论的不确定性推理
基于证据理论的不确定性推理的步骤:
- (1)建立问题的样本空间D。
- (2)由经验给出,或者由随机性规则和事实的信度度量求得基本概率分配函数。
- (3)计算所关心的子集的信任函数值、似然函数值。
- (4)由信任函数值、似然函数值得出结论。




模糊集合
第五章 搜索求解策略
搜索的概念
搜索方向:
- 数据驱动:从初始状态出发的正向搜索。
- 正向搜索——从问题给出的条件出发。
- 目的驱动:从目的状态出发的逆向搜索。
- 逆向搜索:从想达到的目的入手,看哪些操作算子能产生该目的以及应用这些操作算子产生目的时需要哪些条件。
- 双向搜索
- 从开始状态出发作正向搜索,同时又从目的状态出发作逆向搜索,直到两条路径在中间的某处汇合为止。
盲目搜索
- 在不具有对特定问题的任何有关信息的条件下,按固定的步骤(依次或随机调用操作算子)进行的搜索。
启发式搜索
- 考虑特定问题领域可应用的知识,动态地确定调用操作算子的步骤,优先选择较适合的操作算子,尽量减少不必要的搜索,以求尽快地到达结束状态。
状态空间的搜索策略
状态空间
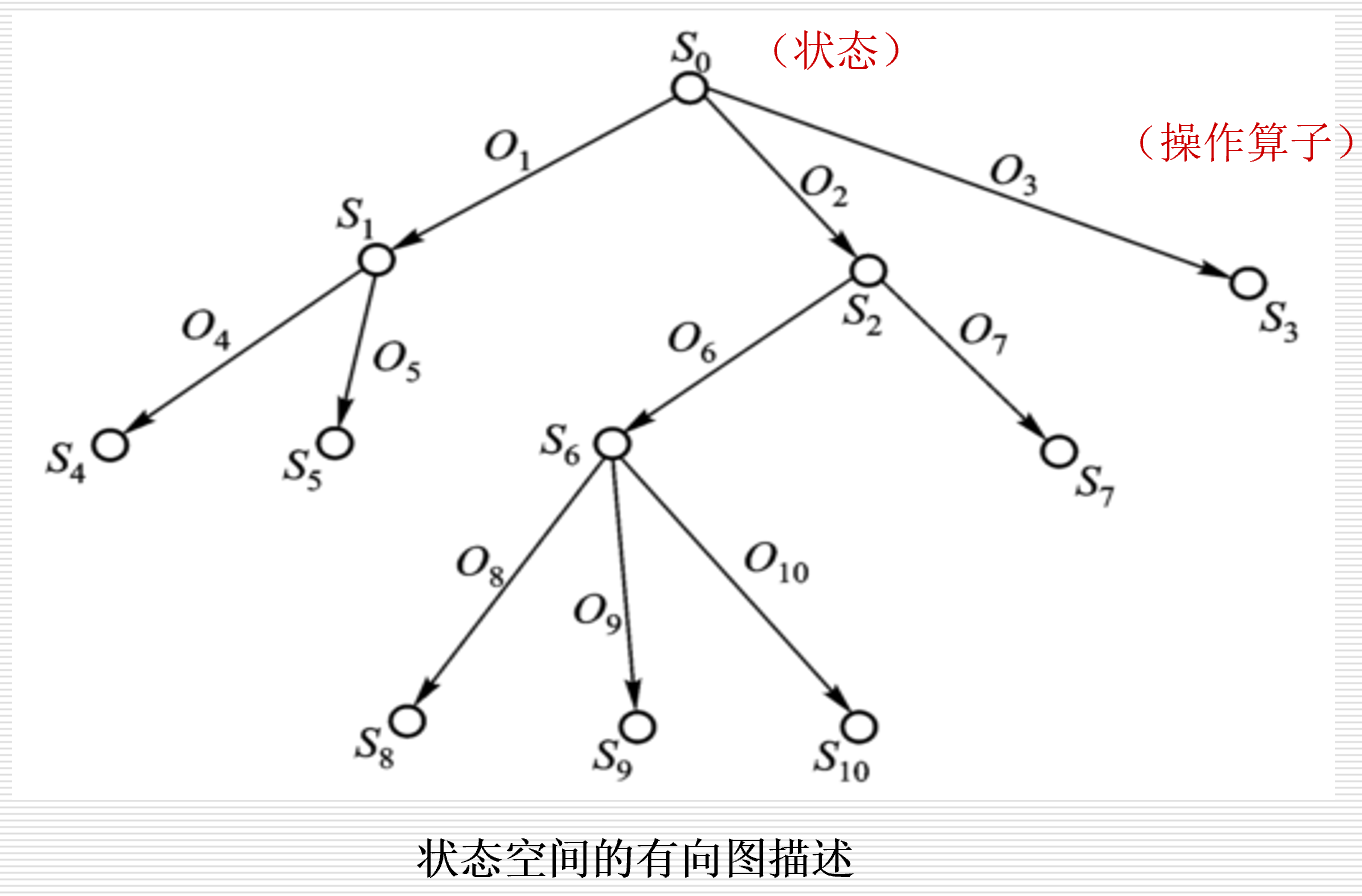
- 利用状态变量和操作符号,表示系统或问题的有关知识的符号体系,状态空间是一个四元组:
$$(S,O,S_0,G)$$ - S:状态集合。
- O:操作算子的集合。
- S0:包含问题的初始状态是S的非空子集。
- G:若干具体状态或满足某些性质的路径信息描述。

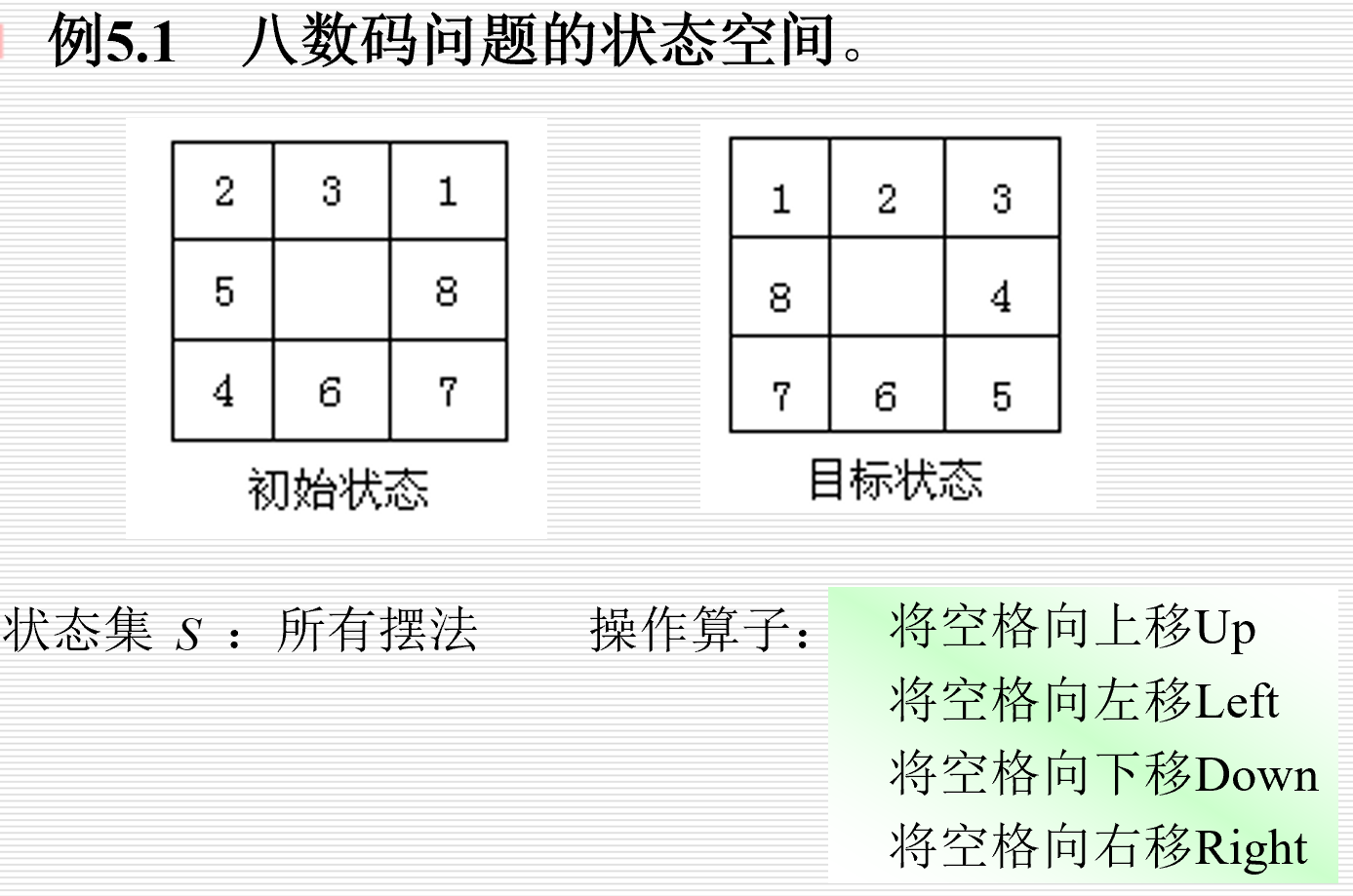
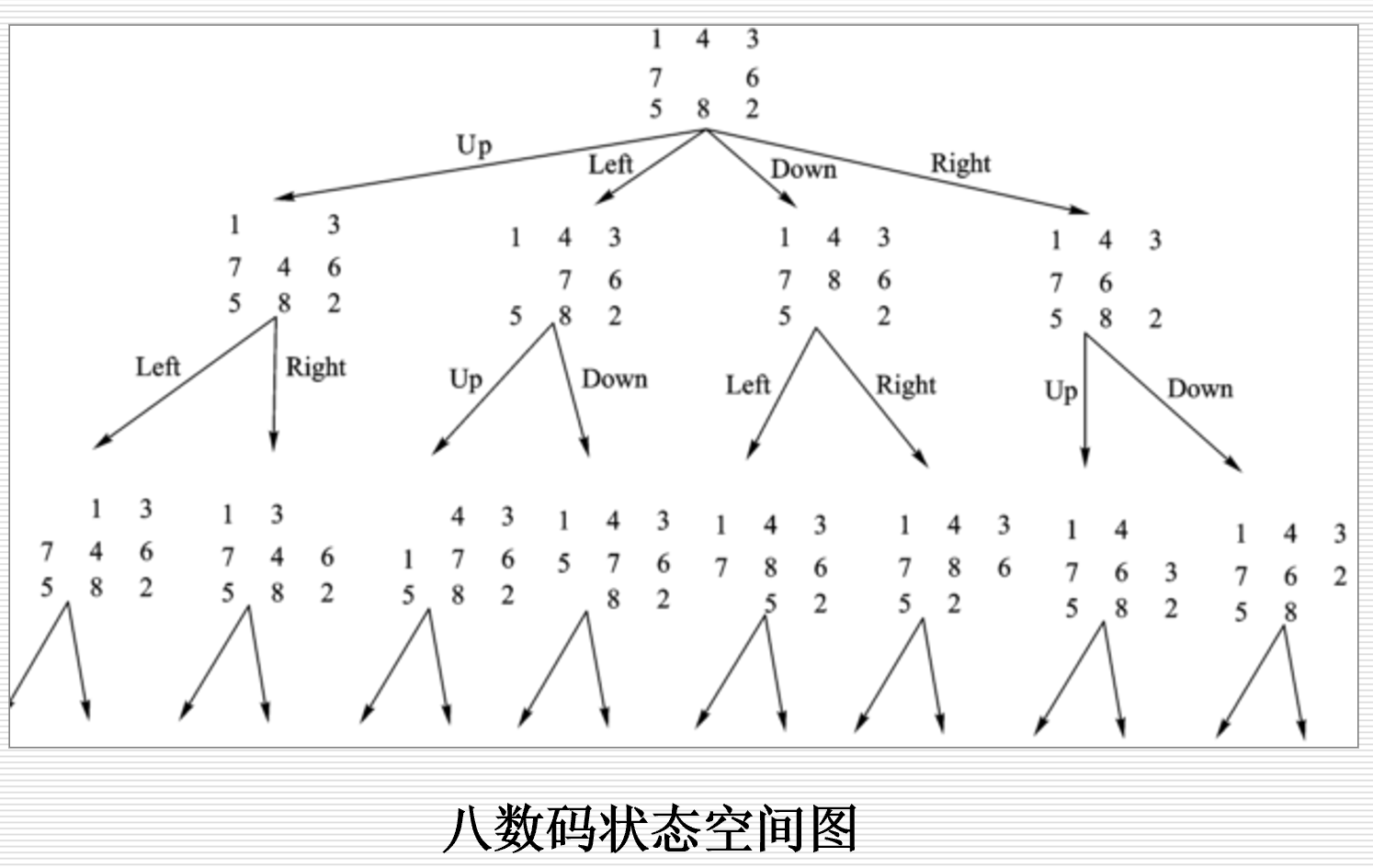
八数码问题的状态空间
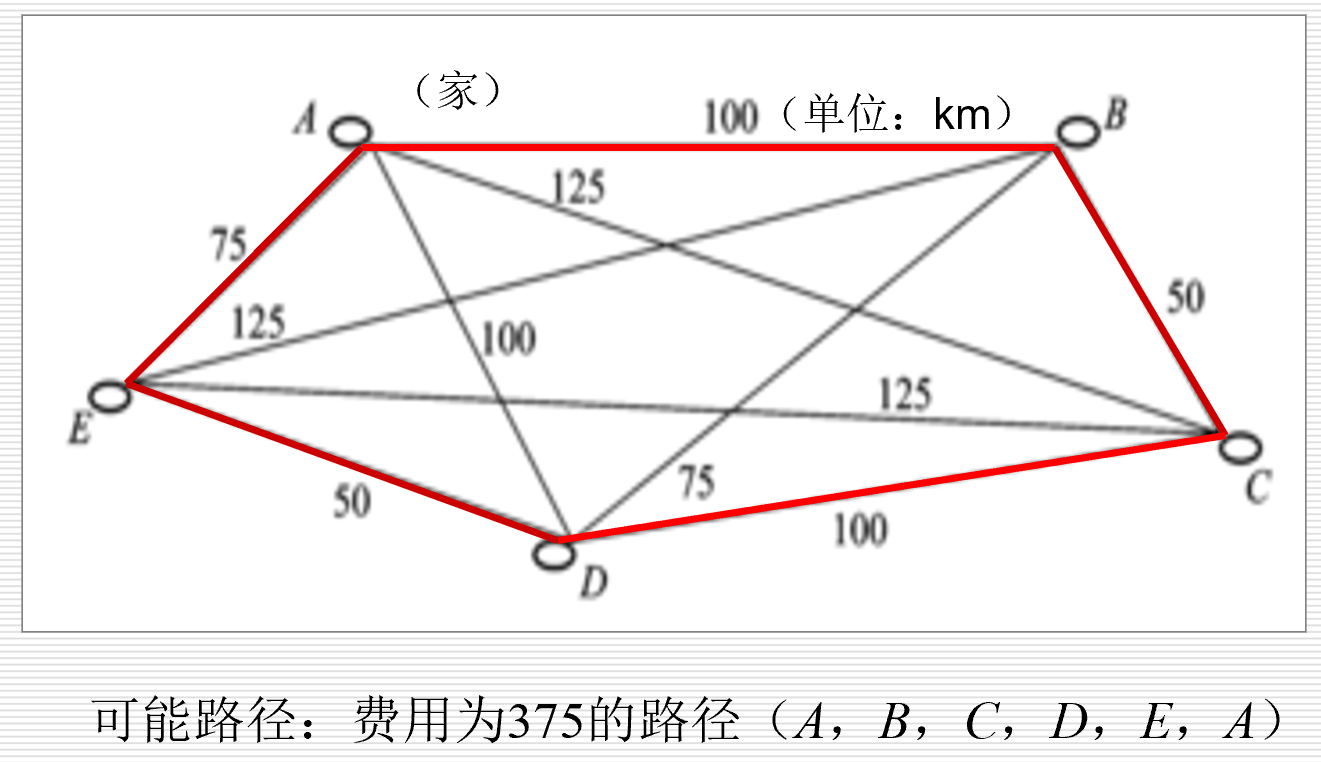
旅行商问题
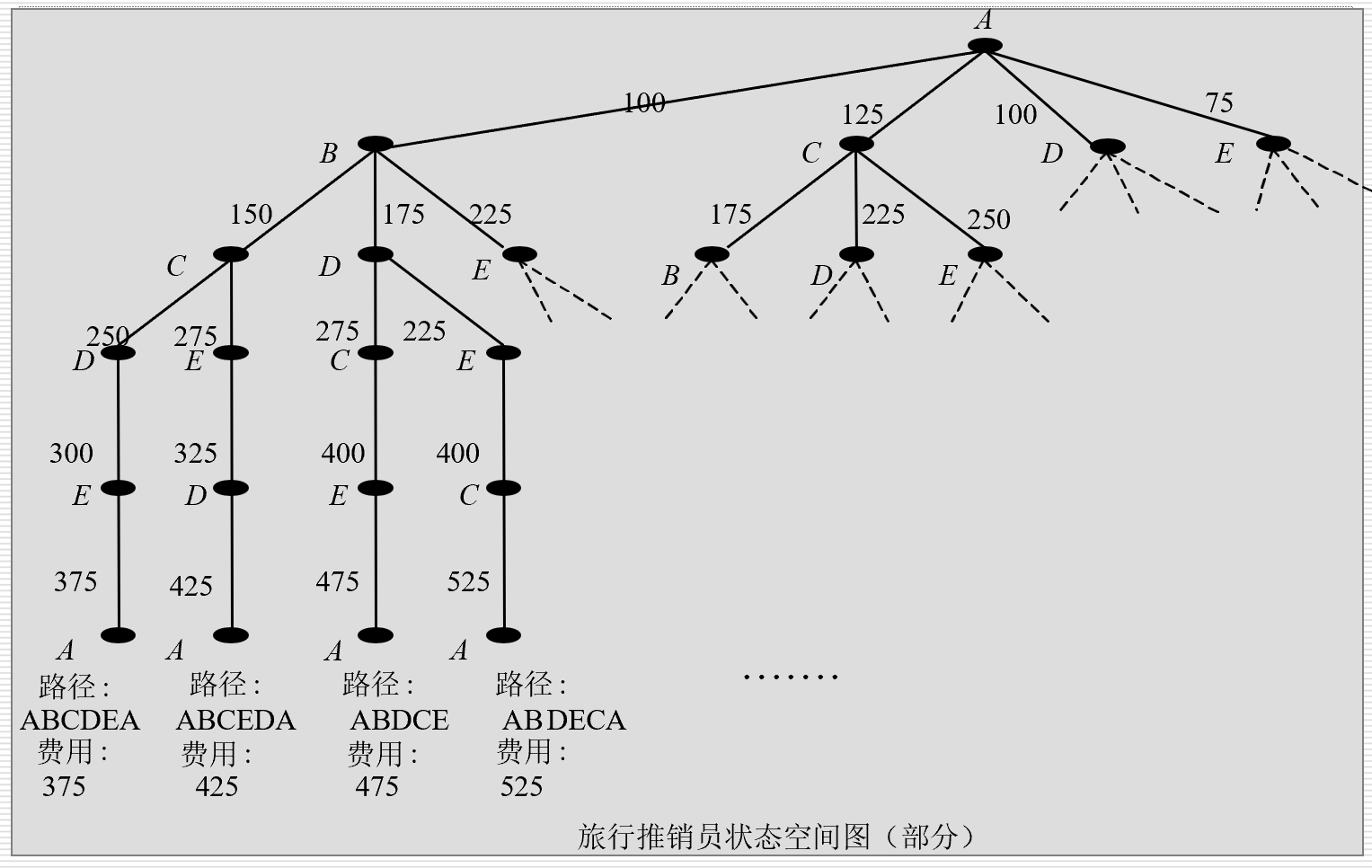
盲目的图搜索策略
带回溯策略的搜索
- 从初始状态出发,不停地、试探性地寻找路径,直到它到达目的或“不可解结点”,即“死胡同”为止。
- 若它遇到不可解结点就回溯到路径中最近的父结点上,查看该结点是否还有其他的子结点未被扩展。若有,则沿这些子结点继续搜索;如果找到目标,就成功退出搜索,返回解题路径。
回溯搜索的算法
- PS(path states)表:保存当前搜索路径上的状态。如果找到了目的,PS就是解路径上的状态有序集。
- NPS(new path states)表:新的路径状态表。它包含了等待搜索的状态,其后裔状态还未被搜索到,即未被生成扩展 。
- NSS(no solvable states)表:不可解状态集,列出了找不到解题路径的状态。如果在搜索中扩展出的状态是它的元素,则可立即将之排除,不必沿该状态继续搜索。
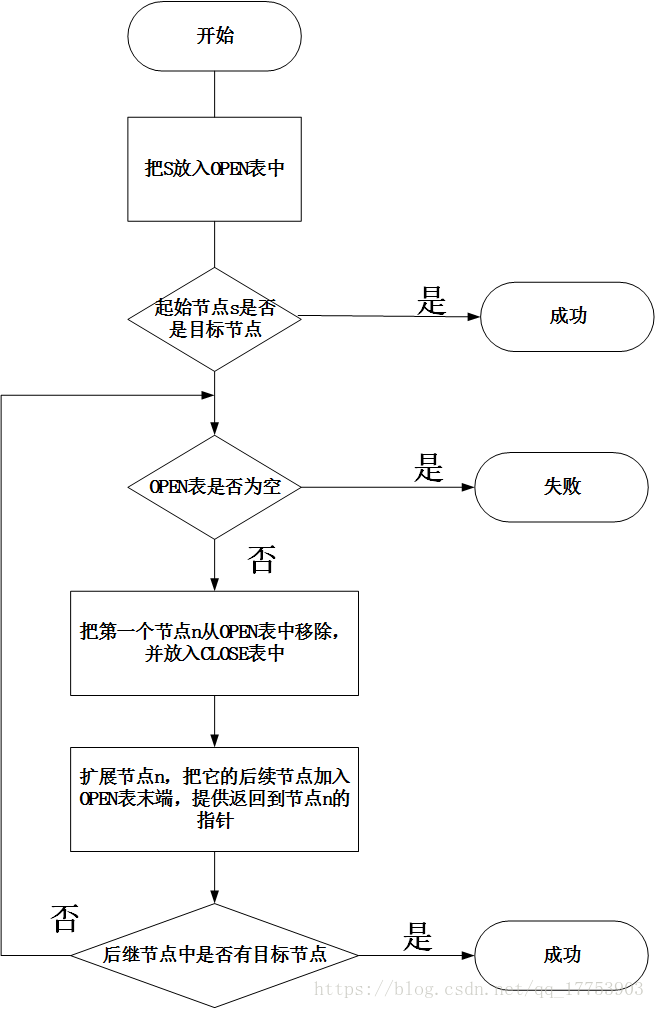
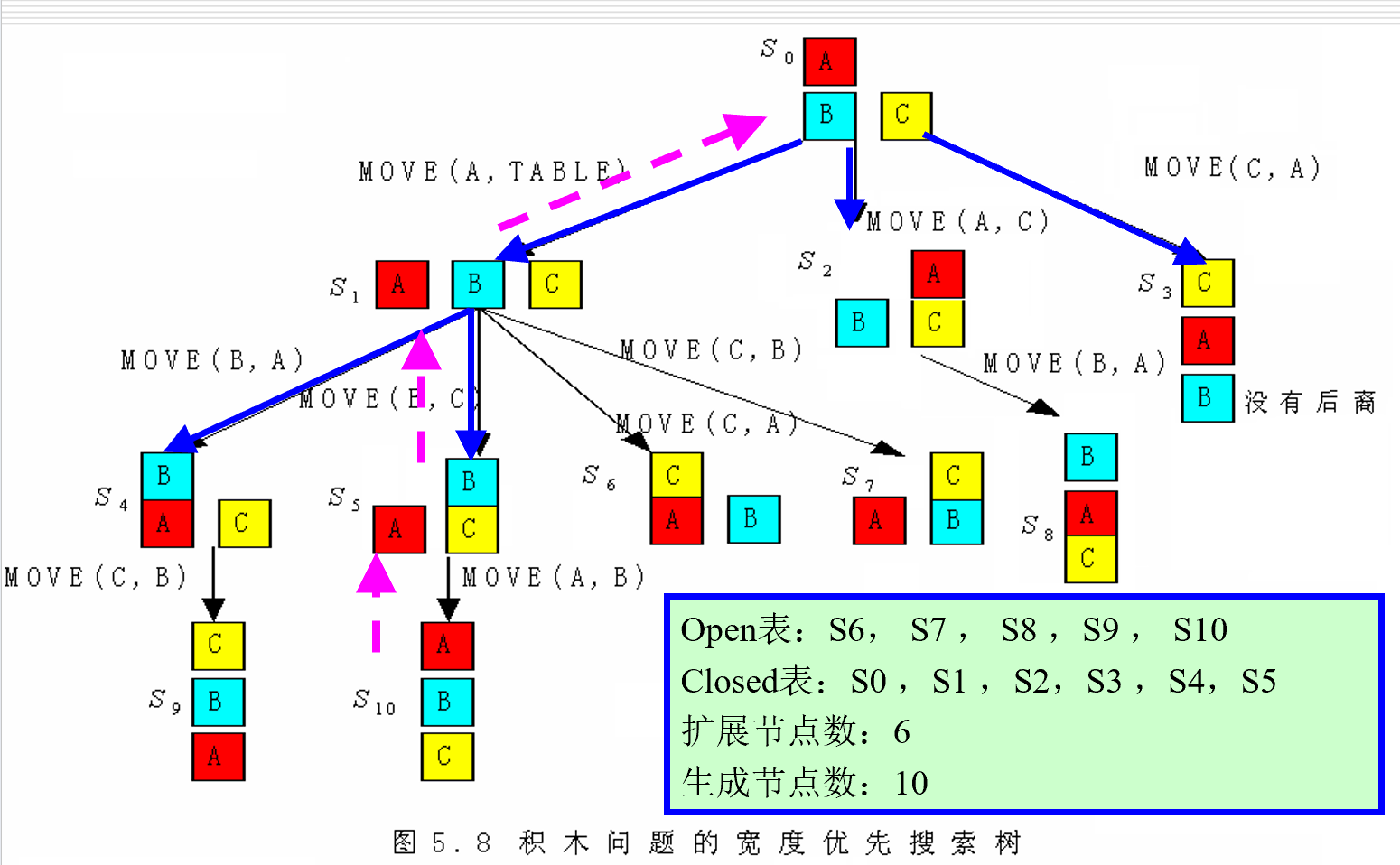
宽度优先搜索
- open表(NPS表):已经生成出来但其子状态未被搜索的状态。
- closed表( PS表和NSS表的合并):记录了已被生成扩展过的状态。
- 例
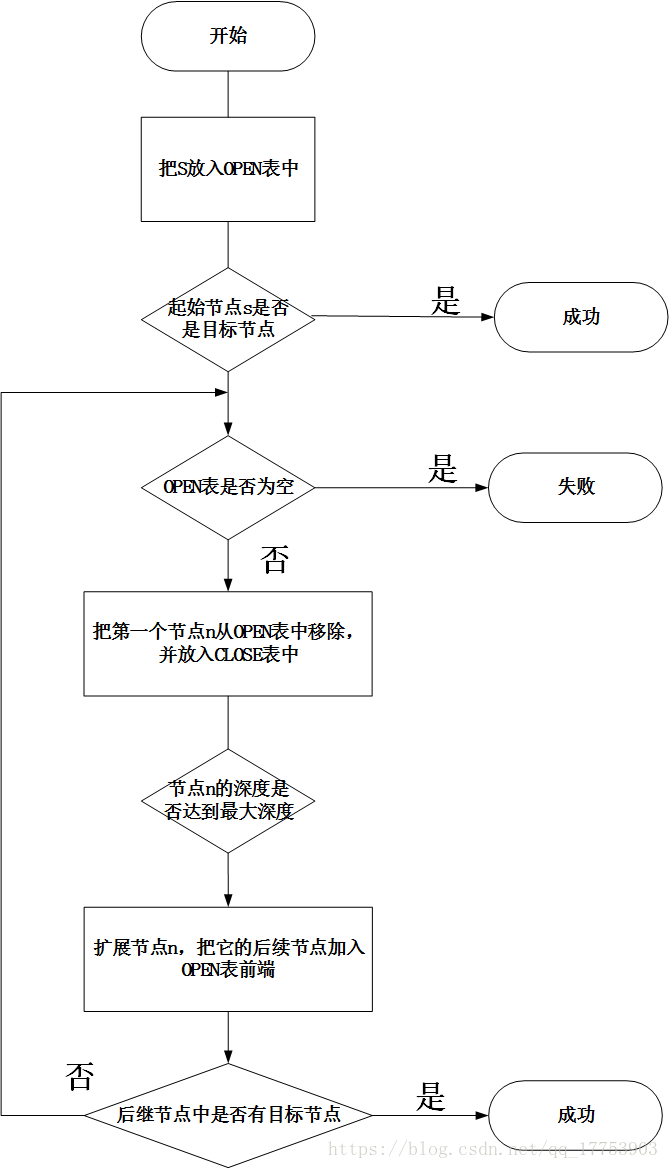
深度优先搜索
启发式图搜索策略
启发信息
- 用来简化搜索过程有关具体问题领域的特性的信息叫做启发信息。
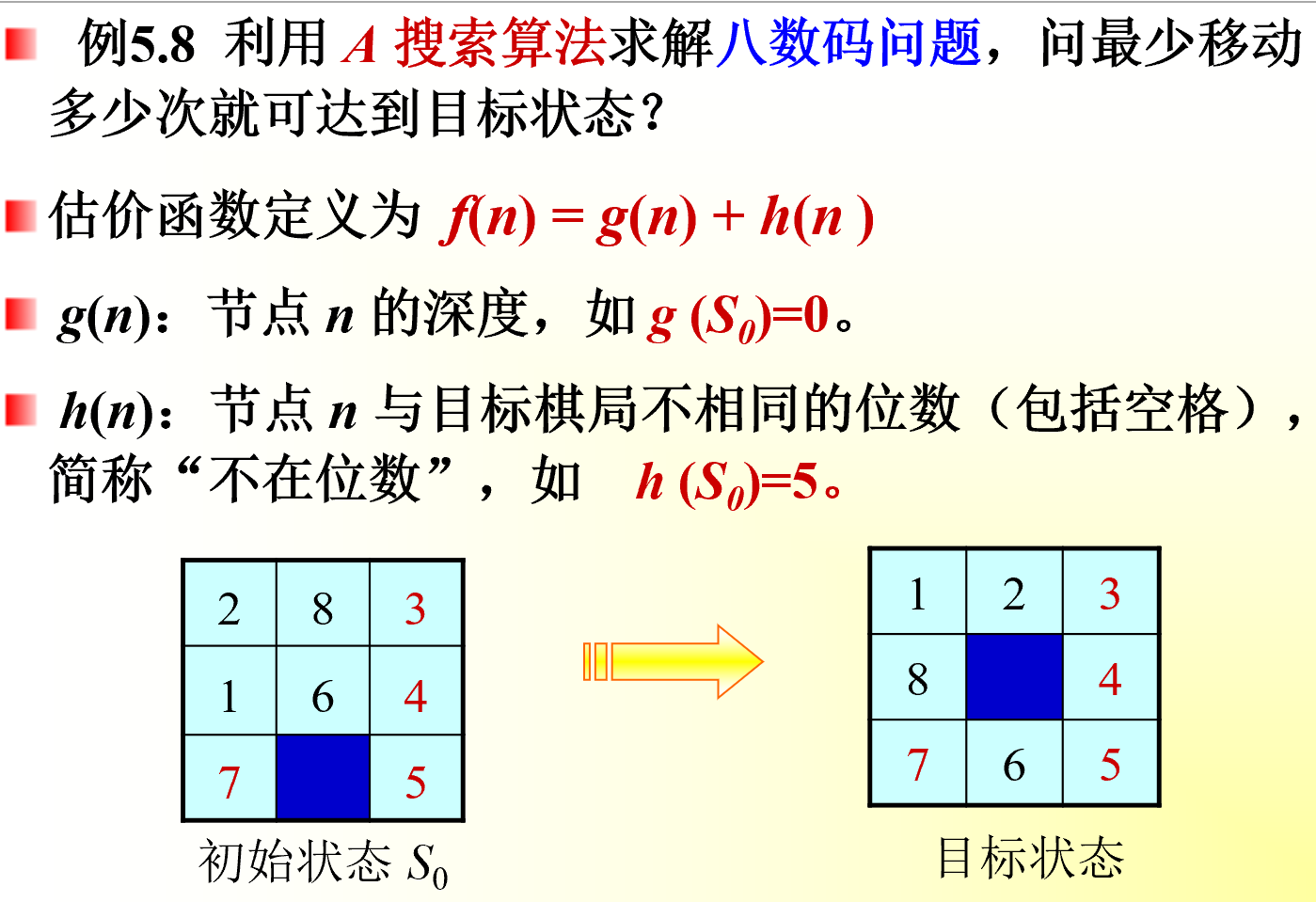
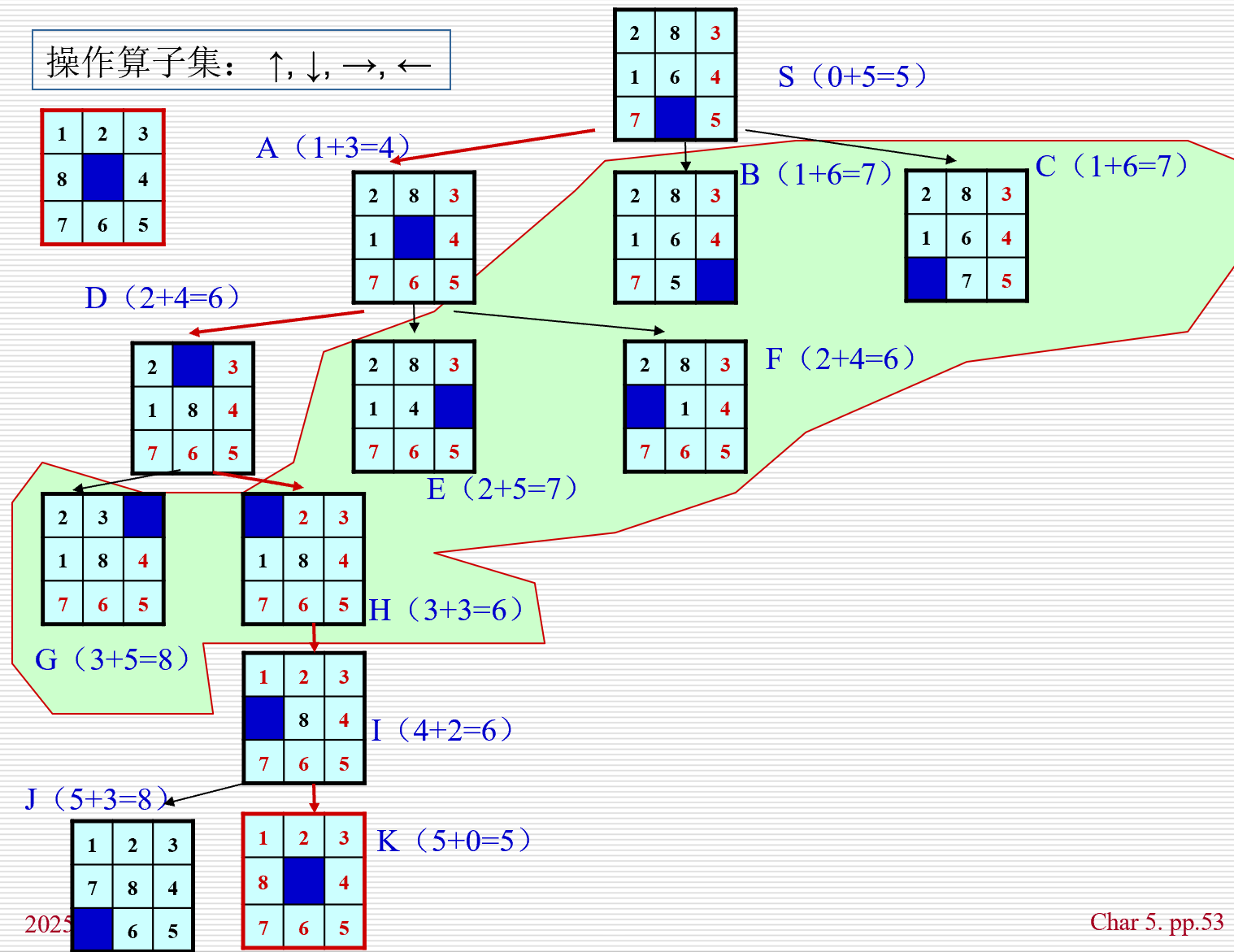
A搜索算法
- 每次扩展结点都对OPEN表中的元素进行排序

第六章 智能计算及其应用
进化算法
- 进化算法(evolutionary algorithms,EA)是基于自然选择和自然遗传等生物进化机制的一种搜索算法。
基本遗传算法
遗传算法
- 遗传算法(genetic algorithms,GA):一类借鉴生物界自然选择和自然遗传机制的随机搜索算法,非常适用于处理传统搜索方法难以解决的复杂和非线性优化问题。
遗传算法的基本思想
在求解问题时从多个解开始,然后通过一定的法则进行逐步迭代以产生新的解。
遗传算法的改进算法
双倍体遗传算法
- 采用显性和隐性两个染色体同时进行进化,提供了一种记忆以前有用的基因块的功能。
多种群遗传算法
- 建立两个遗传算法群体,分别独立地运行复制、交叉、变异操作,同时当每一代运行结束以后,选择两个种群中的随机个体及最优个体分别交换。
自适应遗传算法
- 当种群各个体适应度趋于一致或者趋于局部最优时,使$P_c、P_m$增加,以跳出局部最优;而当群体适应度比较分散时,使$P_c、P_m$减少,以利于优良个体的生存。
群智能算法(swarm algorithms,SI)
- 受动物群体智能启发的算法。
粒子群优化算法
基本思想
- 将每个个体看作n维搜索空间中一个没有体积质量的粒子,在搜索空间中以一定的速度飞行,该速度决定粒子飞行的方向和距离。所有粒子有一个由优化函数决定的适应值。
基本原理
- PSO初始化为一群随机粒子,然后通过迭代找到最优解。在每一次迭代中,粒子通过跟踪两个“极值”来更新自己。第一个就是粒子本身所找到的最优解,这个解称为个体极值。另个一是整个种群目前找到的最优解,这个解称为全局极值。
蚁群算法
基本思想
- 信息素跟踪:按照一定的概率沿着信息素较强的路径觅食。
- 信息素遗留:会在走过的路上会释放信息素,使得在一定的范围内的其他蚂蚁能够觉察到并由此影响它们的行为。
第七章 专家系统与机器学习
专家系统
专家系统定义
- 一类包含知识和推理的智能计算机程序。
专家系统实例
- 医疗诊断专家系统
- 背景:医疗诊断专家系统旨在帮助医生诊断疾病,提供治疗建议。
- 工作原理:
- 知识库:包含大量医学知识,包括疾病症状、诊断规则和治疗方案。
- 推理引擎:使用逻辑推理和规则匹配技术,根据输入的症状和体征,推断可能的疾病。
- 用户界面:医生或患者输入症状,系统输出诊断结果和建议。
- 示例:
- 输入:患者报告发热、咳嗽、喉咙痛。
- 推理过程:
- 系统检查知识库,发现这些症状与流感、感冒、咽炎等疾病相关。
- 系统根据症状的严重程度和持续时间,推断最可能的疾病。
- 输出:系统建议患者可能患有流感,并提供相应的治疗建议,如多休息、饮用温水、服用抗病毒药物等。
机器学习
概念
- 机器学习(Machine learning)使计算机能模拟人的学习行为,自动地通过学习来获取知识和技能,不断改善性能,实现自我完善。
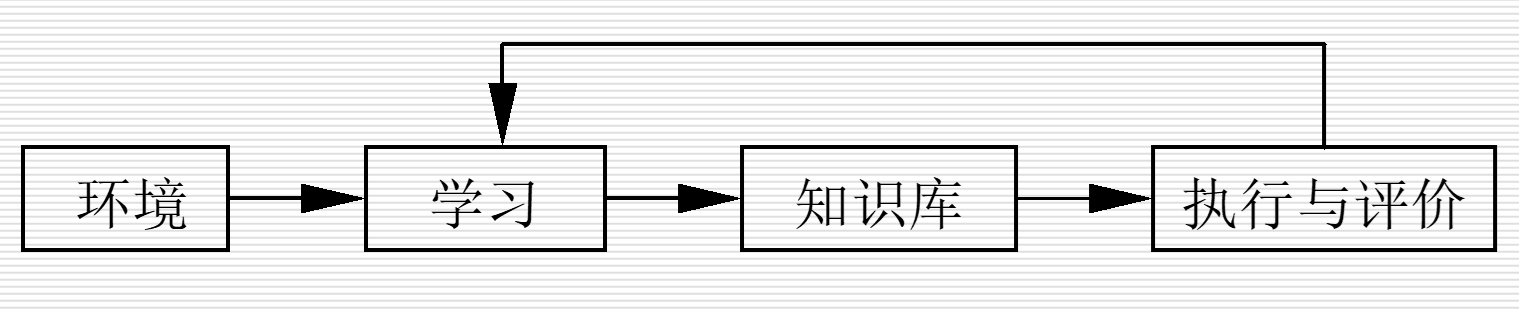
学习系统基本结构
机械式学习
- 记忆学习,或死记式学习:通过直接记忆或者存储外部环境所提供的信息达到学习的目的,并在以后通过对知识库的检索得到相应的知识直接用来求解问题。
指导式学习(learning by being told)
- 又称嘱咐式学习或教授式学习:由外部环境向系统提供一般性的指示或建议,系统把它们具体地转化为细节知识并送入知识库中。在学习过程中要反复对形成的知识进行评价,使其不断完善。
- 指导式学习的学习过程:征询指导者的指示或建议 、把征询意见转换为可执行的内部形式 、加入知识库、评价。
示例学习(learning from examples,实例学习或从例子中学习)
- 通过从环境中取得若干与某概念有关的例子,经归纳得出一般性概念的一种学习方法。
- 示例学习中,外部环境(教师)提供一组例子(正例和反例),然后从这些特殊知识中归纳出适用于更大范围的一般性知识,它将覆盖所有的正例并排除所有反例。
知识发现与数据挖掘
概念
- 知识发现的全称是从数据库中发现知识(KDD)。
- 数据挖掘(DM)是从数据库中挖掘知识。